项目选择: 对cifar,coco数据集进行训练和识别,用训练好的网络做一下应用化的识别工作,如面部识别,车辆识别,标志标牌识别。
项目要求: 1 给出不同的算法,进行比较,最好三种,给出不同情况下的表现。
项目介绍: 技术、依赖选择: 绝大多数机器学习都是用Python做脚本语言。
硬件环境: 训练设备:NVIDIA RTX4060 8G
运行内存:16GB
存储空间:30GB
系统环境:Windows 11
软件环境: 训练环境:Anaconda3 2022-10 + Python 3.9
深度学习框架:PyTorch 2.8.0(CUDA 12.6)
目标检测框架:Ultralytics 8.3.226(支持 YOLOv5/YOLOv8/RT-DETR)
数据处理库:numpy、pandas、scipy
可视化库:matplotlib、seaborn
图像处理库:opencv-python
运行环境: Anaconda,是个科学计算与数据分析包,内置了Python解释器、科学计算工具、包管理与环境环境工具,简单说,就是为科学计算例如机器学习量身定做的环境,里面一些必要的包与解释器已经安装完毕,同时增添或修改其他依赖包也十分简便,它保证了不同项目的解释器版本隔离与项目的顺利运行。
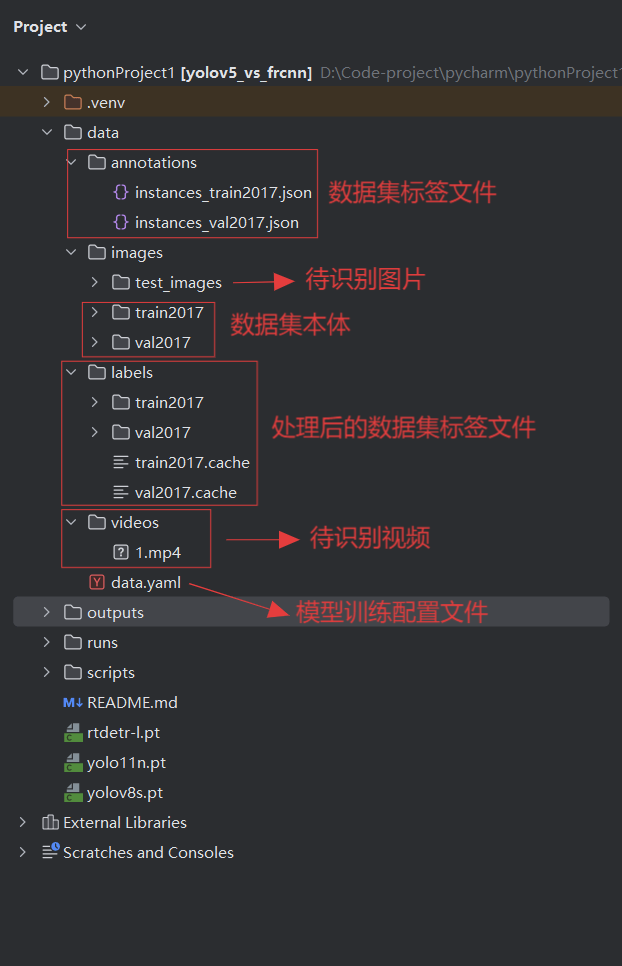
数据集: COCO(Common Objects in Context)是目前最常用的计算机视觉数据集之一,由微软发布,专注于真实场景下的目标检测、实例分割、关键点检测等任务。这里数据集用的coco2017(开源且好用,纯图片),下载好的数据集分为训练集与验证集,同时有对应的json文件(用于标注数据集中图片的信息,例如,分类、分辨率、id等,包含整个训练集或者验证集中所有图片信息,但在这个项目所使用的模型中,无法直接读取json,所以需要先利用Python脚本转换为每张图片对应的txt文件,模型才能进行读取),在模型训练时需要同时读取图片与对应信息。
模型: 这里的模型选择的是yolo系列(这里的模型是指在进行验证时所使用的权重文件+算法,也就是说,训练之前,它只是一个算法,在经过训练集与验证集训练完善以后,得到了训练结果也就是权重文件,那么再次利用训练结果进行验证时,这个时候才叫做模型,简单说,模型=算法+训练权重),我们选用的是封装了yolo系列算法的依赖包ultralytics,除此之外,还封装一些数据分析工具,能够在训练以后,同时生成权重文件与一些训练中的曲线文件(反正是能够反应模型训练是否成功,表现它的反应能力与预测能力),直接在Python环境中pip指令下载这个包即可使用。
验证脚本: 实际上对训练模型的应用就是对算法+训练结果权重的应用。在通过训练后,结果文件夹中会生成权重文件,那么在进行实际应用时,只需要在写一个脚本,写明使用到的权重文件路径、需要识别的图片或者视频路径,再通过opencv分析图片视频,传给模型识别运行,通过Python语法表示即可。
训练结果分析: 对每种模型的训练结果进行对比分析,以此才对比不同模型的性能差异,这里的脚本用到了pandas进行表格制作,matplotlib进行可视化。
整体实现流程: 运行环境搭建与配置→数据集选择下载与转换→模型训练→验证脚本创建与运行→训练结果分析
那么以上就是基础介绍,下面我将对这次课设的项目进行展示介绍,包括但不限于项目目录,目录内容,验证展示等。
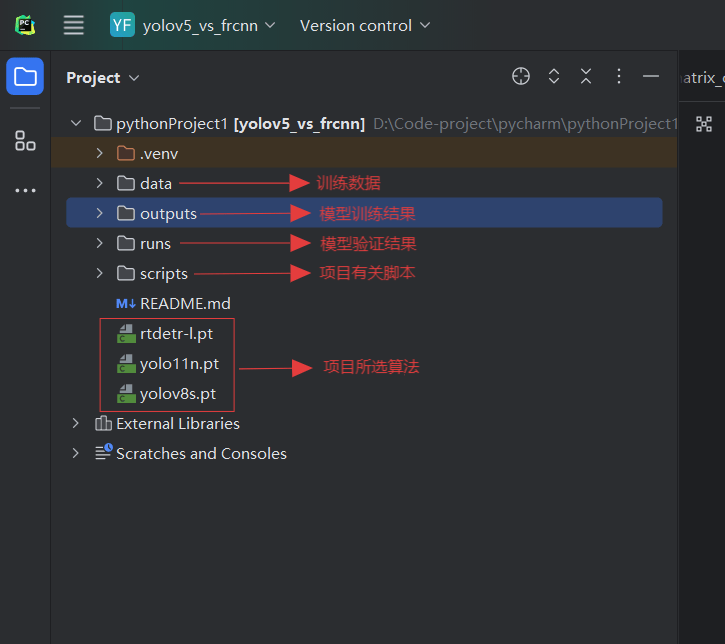
项目展示: 总目录:分为训练数据、模型训练结果、模型验证结果、项目有关脚本四大部分。
训练数据data目录:
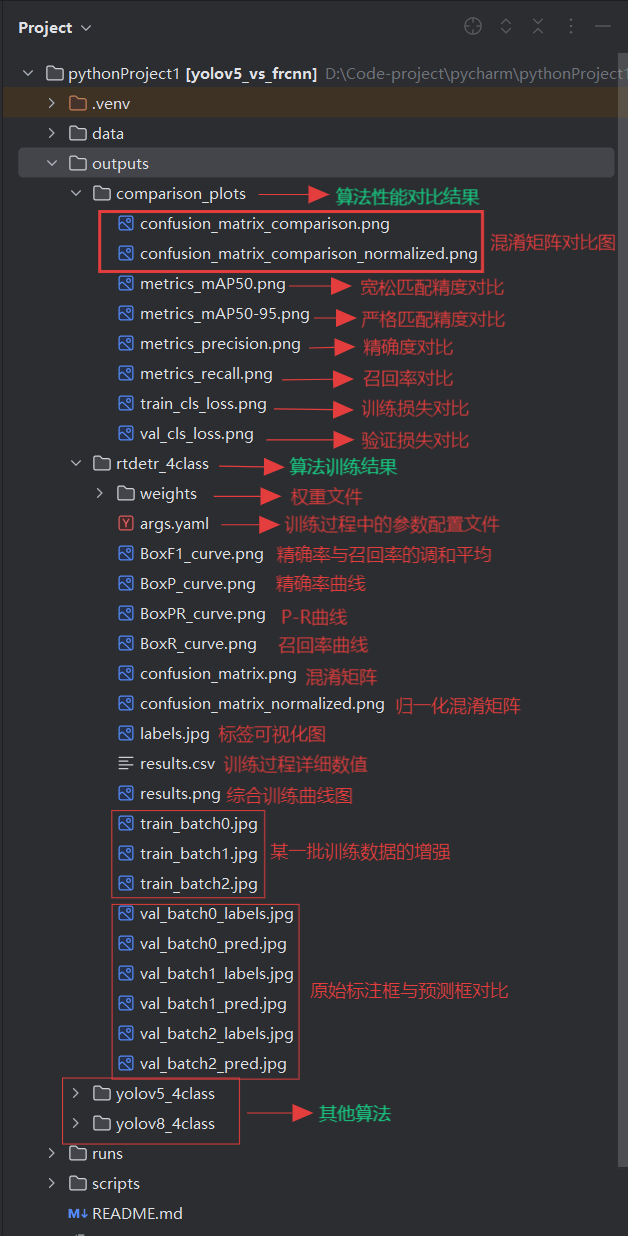
模型训练结果outputs目录:
模型训练结果部分曲线说明: 1. 精确率与召回率的调和平均(F1-score) F1-score 是精确率(Precision)与召回率(Recall)的调和平均,用于综合评价模型的查准率与查全率之间的平衡程度。
取值范围:0 ~ 1,越高表示模型整体表现越好
适用于类别不平衡任务
当 Precision 与 Recall 差距较大时,F1-score 是更稳健的指标
2. 精确率曲线(Precision Curve) 该曲线展示模型在不同阈值设置下的精确率变化情况。
精确率(Precision)表示:被模型预测为某一类别的样本中有多少是真的
随阈值提高,Precision 通常上升
曲线越高说明误报越少,模型判断越“准确”
3. 召回率曲线(Recall Curve) 该曲线展示模型在不同阈值设置下的召回率变化情况。
召回率(Recall)表示:真实属于某类别的样本中有多少被成功识别
阈值降低时,Recall 通常上升
曲线越高表示漏检越少,模型“覆盖能力”更强
4. P-R 曲线(Precision–Recall Curve) P-R 曲线综合展示精确率与召回率的整体表现。
曲线越靠近右上角越好
面积越大(AP 越高)说明模型性能越稳定
适用于类别不平衡场景下的整体指标对比
5. 混淆矩阵(Confusion Matrix) 混淆矩阵展示模型在各个类别上的预测情况,包括正确分类与错误分类的分布。
主对角线表示正确分类数量,越高越好
非对角线的值表示类别之间的混淆
可用于定位模型在哪些类别上性能较弱
6. 归一化混淆矩阵(Normalized Confusion Matrix) 在混淆矩阵的基础上进行比例归一化,使每个类别以百分比展示其预测正确率。
更适用于类别不均衡的数据集
对角线接近 1 表示该类识别准确
能清晰发现模型最容易混淆的类别
7. 标签可视化图(Label / Prediction Visualization) 展示模型在真实图像上的预测结果,可包含:
原图与预测标签
热力图(如 Grad-CAM)
数据类别分布可视化
用于辅助分析模型关注区域及数据整体特征。
8. 训练过程详细数值(Training Log / Metrics) 训练过程中记录的关键数值,如:
Train Loss / Validation Loss(损失曲线)
Train Accuracy / Validation Accuracy(准确率曲线)
学习率(LR)变化
F1 / mAP 随 epoch 的变化
这些数值反映训练稳定性、收敛情况及是否存在过拟合/欠拟合。
9. 综合训练曲线(Overall Training Curves) 将多个指标(Loss、Accuracy、F1、mAP 等)整合在一张图中,用于整体观察模型训练效果。
Loss 应整体下降
Acc/F1/mAP 应整体上升
Train 与 Val 曲线差距小 → 模型泛化能力好
无明显震荡 → 模型训练稳定
模型验证结果runs目录:
项目有关脚本scripts目录:
模型性能对比脚本代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 import osimport pandas as pdimport matplotlib.pyplot as pltimport matplotlib.image as mpimgmodels = [ r"D:\Code-project\pycharm\pythonProject1\outputs\rtdetr_4class" , r"D:\Code-project\pycharm\pythonProject1\outputs\yolov5_4class" , r"D:\Code-project\pycharm\pythonProject1\outputs\yolov8_4class" ] output_dir = r"D:\Code-project\pycharm\pythonProject1\outputs\comparison_plots" os.makedirs(output_dir, exist_ok=True ) ROLLING_WINDOW = 3 def load_results (csv_path ): df = pd.read_csv(csv_path) df.columns = [c.replace('(B)' ,'' ).replace('/' ,'_' ).strip() for c in df.columns] return df def get_common_columns (df_dict ): common_cols = set .intersection(*(set (df.columns) for df in df_dict.values())) return list (common_cols) def plot_common_metrics (df_dict, common_cols, save_dir ): for col in common_cols: if col in ['epoch' , 'time' , 'lr_pg0' , 'lr_pg1' , 'lr_pg2' ]: continue plt.figure(figsize=(8 ,5 )) for model_name, df in df_dict.items(): if col in df.columns: plt.plot(df[col].rolling(ROLLING_WINDOW, min_periods=1 ).mean(), label=model_name) plt.title(col) plt.xlabel("Epoch" ) plt.ylabel(col) plt.grid(True ) plt.legend() plt.tight_layout() plt.savefig(os.path.join(save_dir, f"{col} .png" )) plt.close() def plot_confusion_matrices (models, save_dir, normalized=False ): plt.figure(figsize=(12 ,4 )) n_models = len (models) for i, model_path in enumerate (models): model_name = os.path.basename(model_path) if normalized: cm_file = os.path.join(model_path, "confusion_matrix_normalized.png" ) else : cm_file = os.path.join(model_path, "confusion_matrix.png" ) if not os.path.exists(cm_file): print (f"⚠️ {cm_file} 不存在,跳过" ) continue img = mpimg.imread(cm_file) plt.subplot(1 , n_models, i+1 ) plt.imshow(img) plt.axis('off' ) plt.title(model_name) plt.tight_layout() suffix = "_normalized" if normalized else "" plt.savefig(os.path.join(save_dir, f"confusion_matrix_comparison{suffix} .png" )) plt.close() print (f"✅ 混淆矩阵对比图已生成 {suffix} " ) df_dict = {} for model_path in models: model_name = os.path.basename(model_path) csv_file = os.path.join(model_path, "results.csv" ) if not os.path.exists(csv_file): print (f"⚠️ {csv_file} 不存在,跳过" ) continue df = load_results(csv_file) df_dict[model_name] = df if not df_dict: print ("❌ 没有可用的结果文件,退出" ) exit() common_cols = get_common_columns(df_dict) print ("✅ 公共列:" , common_cols)plot_common_metrics(df_dict, common_cols, output_dir) plot_confusion_matrices(models, output_dir, normalized=False ) plot_confusion_matrices(models, output_dir, normalized=True )
数据集标签处理脚本代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import jsonimport osfrom tqdm import tqdmjson_path = "data/annotations/instances_val2017.json" images_dir = "data/images/val2017" labels_dir = "data/labels/val2017" os.makedirs(labels_dir, exist_ok=True ) with open (json_path, "r" , encoding="utf-8" ) as f: data = json.load(f) categories = {cat["id" ]: cat["id" ] - 1 for cat in data["categories" ]} images = {img["id" ]: {"file_name" : img["file_name" ], "width" : img["width" ], "height" : img["height" ]} for img in data["images" ]} annotations = {} for ann in data["annotations" ]: img_id = ann["image_id" ] bbox = ann["bbox" ] category_id = ann["category_id" ] if img_id not in annotations: annotations[img_id] = [] annotations[img_id].append((category_id, bbox)) for img_id, info in tqdm(images.items(), desc="Converting JSON → YOLO labels" ): if img_id not in annotations: continue txt_path = os.path.join(labels_dir, os.path.splitext(info["file_name" ])[0 ] + ".txt" ) w, h = info["width" ], info["height" ] lines = [] for category_id, bbox in annotations[img_id]: x_min, y_min, bw, bh = bbox x_center = (x_min + bw / 2 ) / w y_center = (y_min + bh / 2 ) / h width = bw / w height = bh / h class_idx = categories[category_id] lines.append(f"{class_idx} {x_center:.6 f} {y_center:.6 f} {width:.6 f} {height:.6 f} " ) with open (txt_path, "w" ) as f: f.write("\n" .join(lines))
图片识别脚本代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 from ultralytics import YOLOimport osimport timeimport shutildef main (): model_path = r"D:\Code-project\pycharm\pythonProject1\outputs\yolov5_4class\weights\best.pt" source = r"D:\Code-project\pycharm\pythonProject1\data\images\test_images" timestamp = time.strftime("%Y-%m-%d_%H-%M-%S" ) save_dir = fr"D:\Code-project\pycharm\pythonProject1\runs\detect\predict_{timestamp} " show_results = False save_results = True save_txt_results = False os.makedirs(save_dir, exist_ok=True ) model = YOLO(model_path) temp_dir = os.path.join(os.path.dirname(save_dir), "temp_results" ) if os.path.exists(temp_dir): shutil.rmtree(temp_dir) results = model(source, save=True , project=temp_dir, name="temp" , exist_ok=True ) for idx, r in enumerate (results): img_name = os.path.basename(r.path) txt_path = os.path.join(save_dir, os.path.splitext(img_name)[0 ] + ".txt" ) print (f"预测图片路径: {r.path} " ) print (r.summary()) if show_results: r.show() if save_txt_results: r.save_txt(txt_file=txt_path) temp_output_dir = os.path.join(temp_dir, "temp" ) if os.path.exists(temp_output_dir): for file in os.listdir(temp_output_dir): shutil.move(os.path.join(temp_output_dir, file), save_dir) shutil.rmtree(temp_dir) print (f"✅ 所有预测结果已保存到: {save_dir} " ) if __name__ == "__main__" : main()
视频识别脚本代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 from ultralytics import YOLOimport cv2import numpy as npdef main (): model_path = r"D:\Code-project\pycharm\pythonProject1\outputs\yolov8_4class\weights\best.pt" source = r"D:\Code-project\pycharm\pythonProject1\data\videos\1.mp4" model = YOLO(model_path) cap = cv2.VideoCapture(source) if not cap.isOpened(): print (f"❌ 无法打开视频源: {source} " ) return width = int (cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int (cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) fps = cap.get(cv2.CAP_PROP_FPS) or 30 print (f"🎥 正在处理视频: {source} " ) print (f"分辨率: {width} x{height} , FPS: {fps} " ) while True : ret, frame = cap.read() if not ret: print ("✅ 视频结束或无法读取帧。" ) break frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) results = model(frame_rgb) r = results[0 ] annotated_frame = np.array(r.plot(), dtype=np.uint8) annotated_bgr = cv2.cvtColor(annotated_frame, cv2.COLOR_RGB2BGR) cv2.imshow("YOLO Video Detection (Press Q to quit)" , annotated_bgr) if cv2.waitKey(1 ) & 0xFF == ord ('q' ): break cap.release() cv2.destroyAllWindows() print ("✅ 检测结束,窗口已关闭。" ) if __name__ == "__main__" : main()
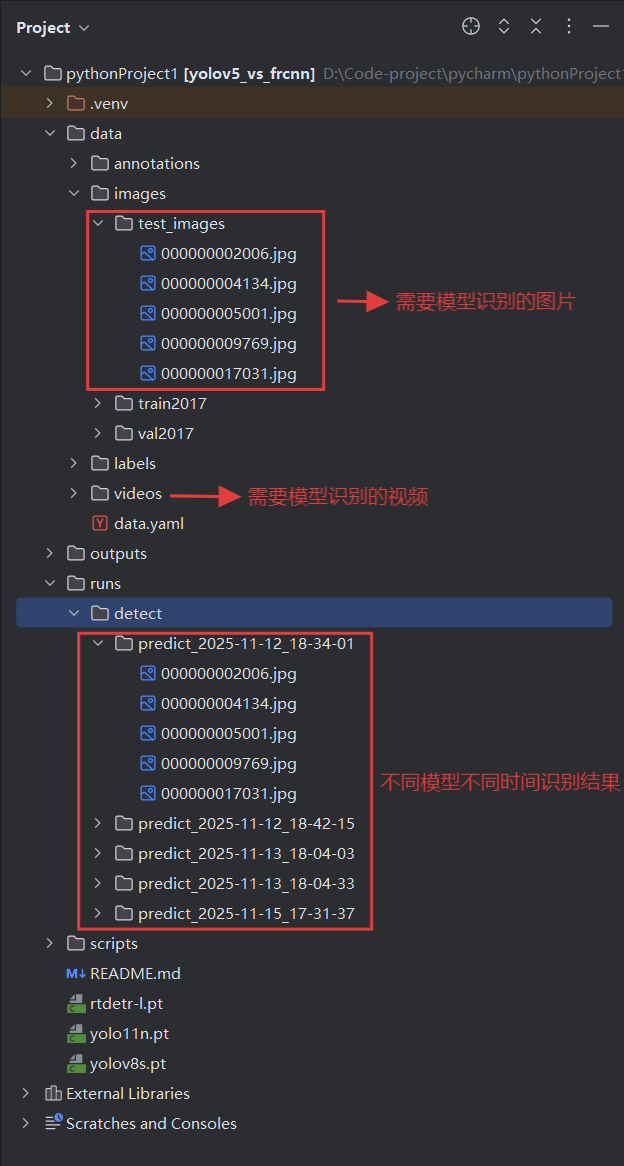
识别成果展示(一张为例): 待识别图片:
已识别结果: